
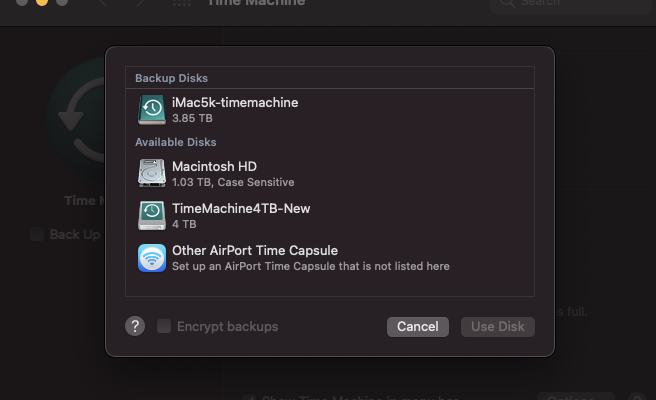
I use an external 4TB HDD to backup all my macs via Time Machine. I first hooked it up to a Raspberry Pi, but the Linux drivers were not very reliable. Instead, I connected it to my iMac and shared it via SMB/AFP (AFP is no longer available on Big Sur) with a specific user named timemachine over the network. All other macs connected to this share once, and they automatically backup via the iMac on that disk every day. …
Blog Posts
Many of the books that I wanted to read on my Kindle(s), were in Arabic or Persian, and were also available freely online. These books were not of .mobi format, …
In this post, we will go through the process of deep copying a PHP variable in user land (i.e., in pure PHP) step by step, describing the challenges facing every …
[—TOC Header:Table of Contents—][—ATOC—] [—TAG:h3—] PHP Emulator is a PHP interpreter written in PHP (somewhat like PyPy). It was created with many goals in mind, particularly allowing fine-grained low-level control over …
While working on PureTextRender package, I realized some serious limits in PHP arrays. The mentioned package renders text into BMP images using pure PHP (no GD), and for that it …
If you’re here because you were at my Black Hat USA 2014 Taintless talk, and you wanted to solve that challenge; here’s a clearer image of my t-shirt: The presentation and …
Stripe is a financial firm, which runs CTF competitions of highest quality. This year, around today (22 Jan) they launched their third CTF, which is based on distributed computing (the …
Last week UVa Cavaliers had a football game with GATech, and I really wanted them to win, cuz I hate GeorgiaTech, but they lost. The odd thing was, in the …
NOTE: the script is not functional at the moment (due to facebook API changes). I will remove this note once I make a new working version. Update Sep 2014: I’ve …
First of all, Happy Nowruz! Tomorrow is officially the new Jalali year‘s start. Best of wishes to everyone. The Problem I’ve been working on an elegant design for a new …